About
MultiMoco NTU 為臺大語言所謝舒凱老師主持之知識本體、語言處理與人文計算實驗室(LOPE)建置之多模態語料庫。本計畫借助美國加州大學洛杉磯分校(UCLA)Red Hen 實驗室團隊之多模態語料分析技術,錄製數位電視公共頻道、擷取臺灣立法院議事轉播,收錄數種臺灣國家語言(華語、閩南語、客家語、原住民族語等), 在跨文化交流的模態分析中,更廣泛且深入地探究各種語言構式。語言的形式和語意將不再受限於純文字,而是開闢了多模態表達的可能性——例如手勢、肢體動作和臉部表情,以實現人們之間相互溝通、理解之目標。
1. Search
1.1 Look for a keyword
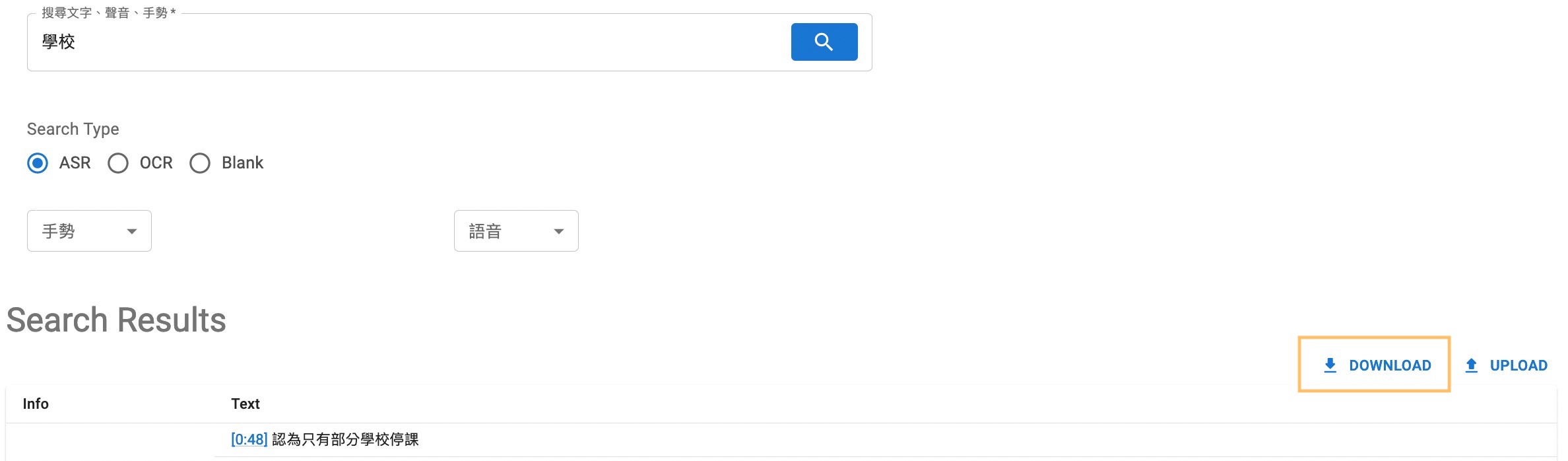
At the Home Page , we
can enter a keyword for our subject of concern (e.g., 學校
'school') in the search bar.
Then, click on the 'Search'
button which will lead us to the
Result Page .

1.2 Browse the results
The Result Page is
divided into four sections: (a) search bar, (b) search type, (c)
display options, and (d) table of search resulrs.
The
details of these sections are illustrated below:
- (a) search bar
- We can search for another keyword and get another table of results.
- (b) search type
-
We can choose to search for different type of texts (
ASR | OCR | Blank )* for our keyword.
For the example in the below picture, if we search for 學校 and select ASR,
the corpus will go through all ASR data and return the texts with 學校. - (c) display options
- After we aquire the search results, we can choose to show more information happening simultaneously with the texts. That is, the details of the gestures ( Hand movement | Palm visibility ) and sound ( Overlapping ).
- (d) search results
-
The table of search results comprises two columns (
Info | Text ).
For each matching video, the information for its source channel, date, and filename.
Within the first video, 15 texts are found with 學校 at 15 different time points.
*ASR: texts generated via Automatic Speech Recognition
OCR: texts generated via Optical Character Recognition
Blank: blank segments recognized via
Allosaurus
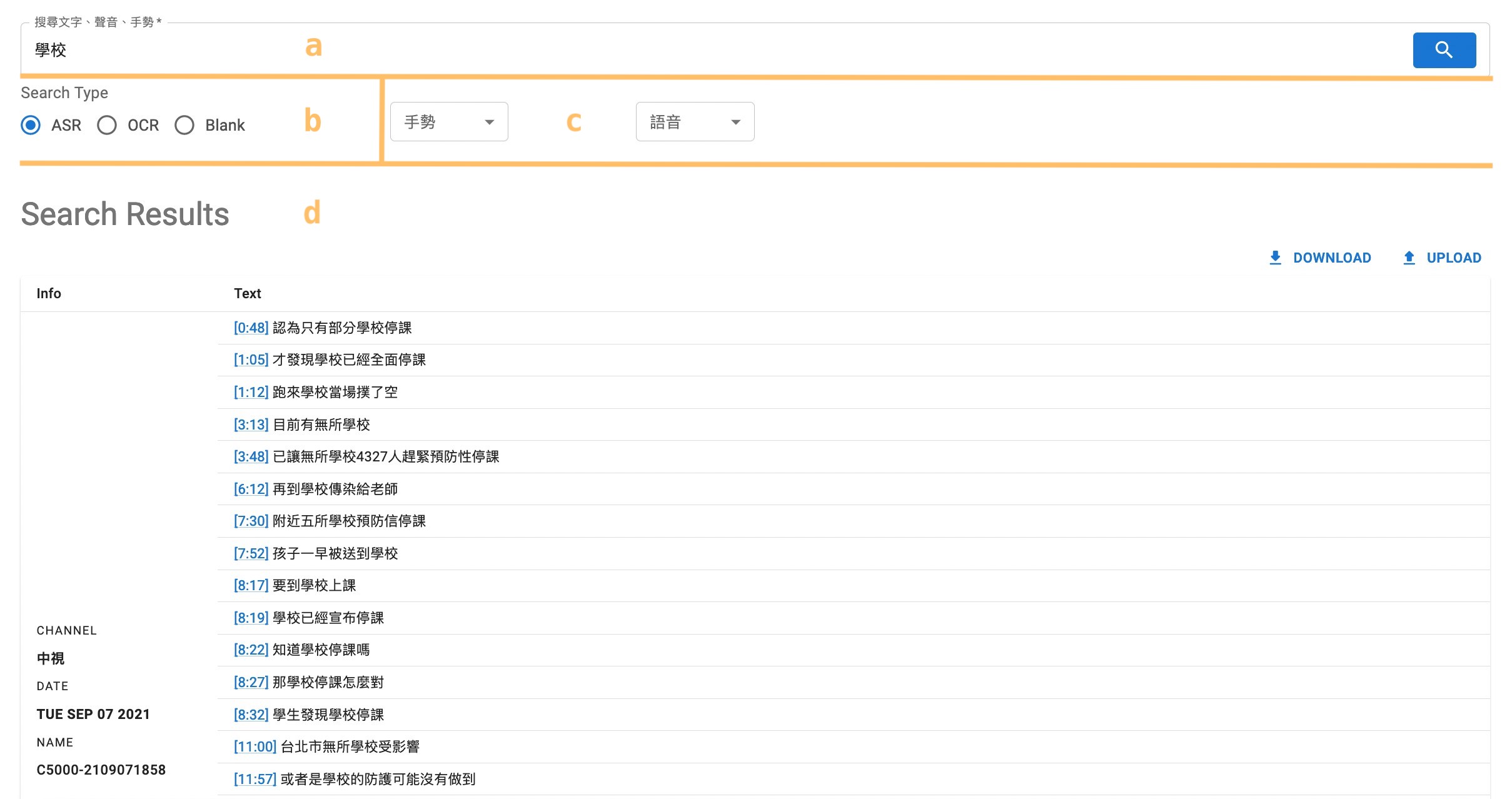
1.3 Check a specific result
We can take a closer look at the result texts by clicking on the
timepoint.
For example, we can click on the timepoint of
the first matching text
[0:48]
Then, we can
see its corresponding image as well as the recognized phonemes,
and the sound wave sorrounding the timepoint.
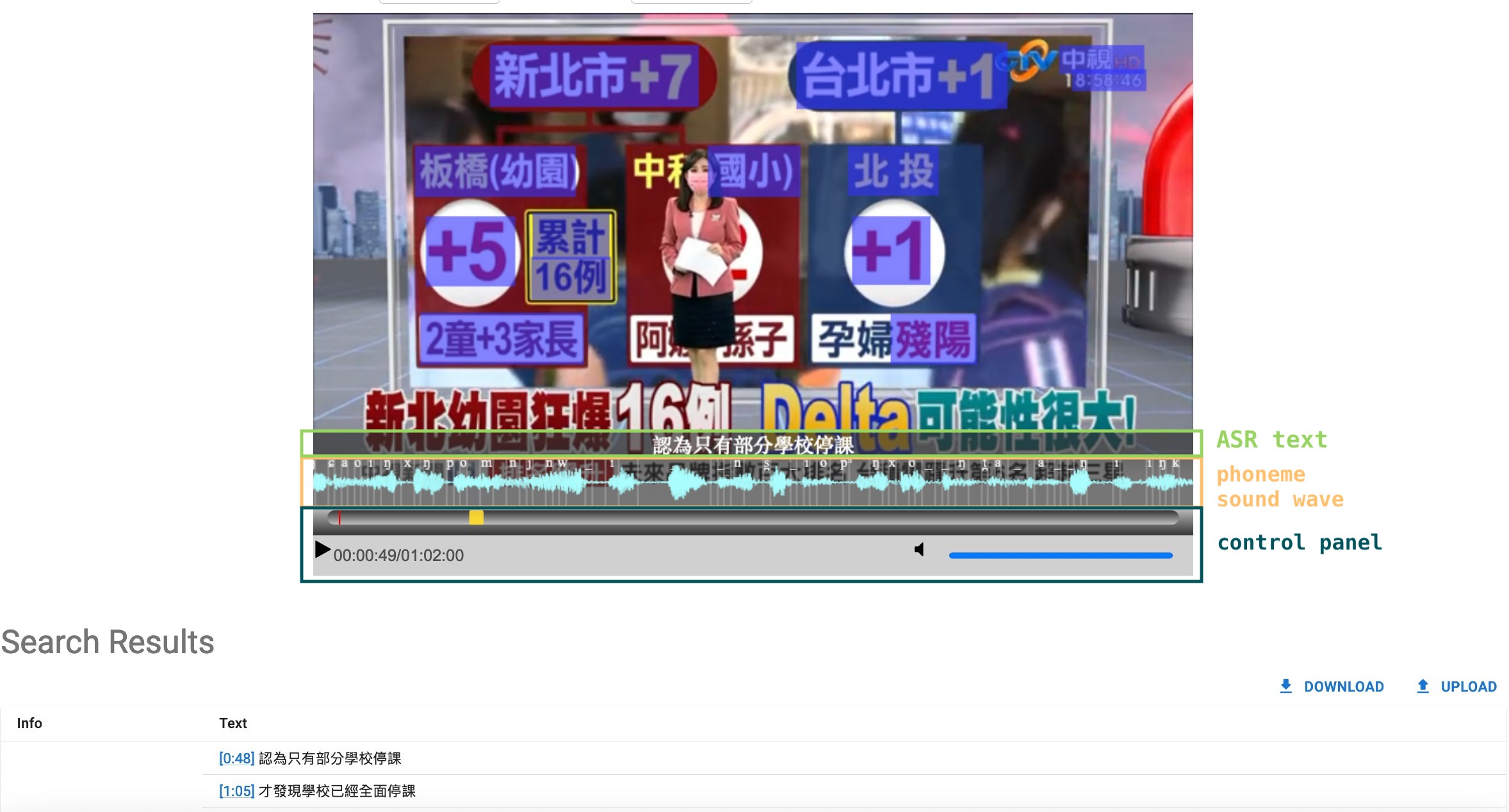
2. Annotate
2.1 Select a segment
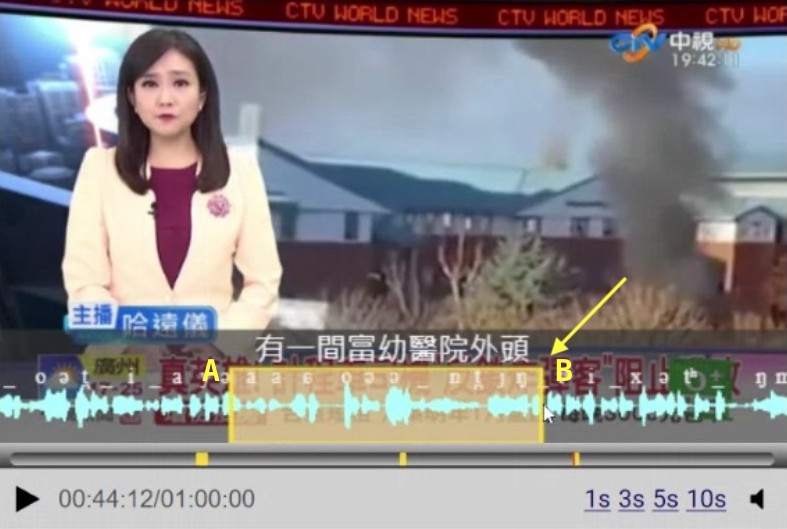
The steps for annotating on MOCO are similar to the methods used in other tools, such as Praat or ELAN.
We can specify a frame by clicking on a point (A) on the waveform and then drag back to another point (B), as shown in the picture below.
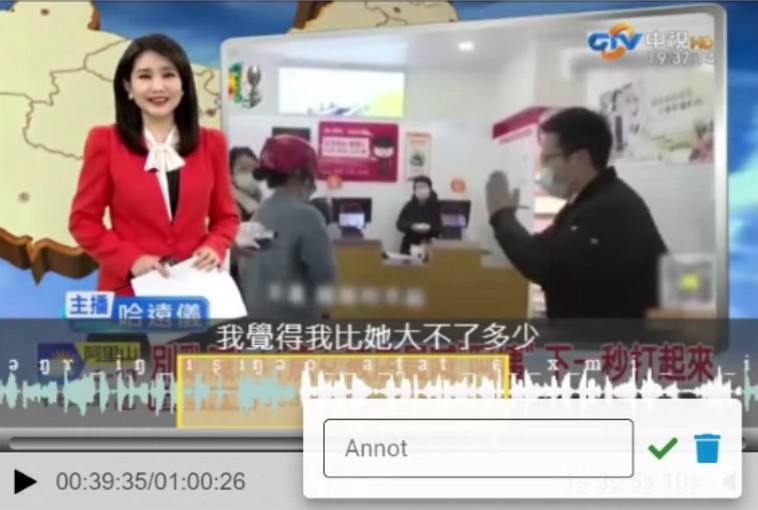
2.2 Annotate the target segment
After we specify the segment, we can click on the yellow frame; then, we can enter our annotation in the pop-up box and save it by clicking the green check mark.
2.3 Download the results and annotations
When we finish annotating, we can download the results and annotations by clicking the Download button on the right top corner of the results.
The table along with the specified annotations will be downloaded in the form of a .csv file, which can be easily opened by spreadsheet tools or processed via programming languages.
Project Details
Hardware Setup
We have combined a server with Debian Linux OS installed, a NAS with 4x8TB of hard drive disk mounted in RAID 5, and a SiliconDust HDHomeRun TV Tuner as our preliminary capture station. To enhance signal quality, we have an outdoor antenna connected via a coaxial cable. Also, both the server and the NAS are powered by a UPS with their network connections isolated from the main LAN by a router to ensure our data is secured physically and virtually.
Source Media
All 22 Taiwanese digital terrestrial television channels use the European-based DVB-T standard for broadcast transmission with their content accessible and recordable using a commercial TV tuner. We will mainly focus on 10 channels, including news of different Taiwanese languages and the consultation of the parliament, listed as follows: CTV News PTS News, PTS Taigi, Hakka TV, Taiwan Indigenous TV, TTV News, CTS News, Congress Channel I, Congress Channel II, and FTV News.
Traditionally, the main news channels are broadcasted during morning, noon, and evening in Taiwan. Nevertheless, since most of the morning news is Mandarin-speaking, in order to meet the highest common factor of the four language categories we set up previously; plus, on account of the storage capacity, recording will be deployed during the evening time slots marked in bold above. Further, in both time slots, either one Mandarin channel will be chosen and take turns daily or weekly. In total, there will be five hours of news recorded every day, including two hours for Mandarin, and one hour each for Hokkien, Hakka, and Formosan languages. As for the congress channel, since all sessions are available on the Taiwan Parliament’s website with dedicated transcriptions in Mandarin, the data will be crawled directly from the Internet instead of recorded by the tuner. On the other hand, we are also planning to record talk shows, soap operas, and documentaries of the four language categories. Details will be provided in future communication.
Test Drive
We have successfully recorded the first batch of news during August 5-6. The resolution of the raw file captured by HDHomeRun is at 1080p and encoded in H.264. In this case, there would be a massive 2 GB per hour file size. After post-processing, the video is compressed at 720p and re-encoded in H.265. The compression process takes another hour to finish, while the result turns out to be the more acceptable 350MB per hour file size. As mentioned earlier, 5 hours of news, plus an hour of congress consultation –– a total of six hours recording, consuming approximately 2.1 GB of storage daily. Our NAS, with 20.95 TB of free space, will be able to maintain continuous recording for 9,976 days, which is considerably sufficient.
Preprocessing
The priority of dealing with audio data of news recording is the speech-to-text procedure. We have been evaluating two service offers, one is Google Speech-to-Text API, and the other is Philips Dictation. The former charges USD$ 0.006/15 sec, while the latter is free for academic use. Both services support Traditional Chinese output with high confidence, while the latter only accepts direct input via a microphone. We are still considering which is more suitable. On the other hand, it is worth noticing that the speech-to-text service is limited to Mandarin only. When it comes to other Taiwanese languages, we are looking forward to hiring students with language-specific knowledge for manual transcribing.
After entering the NLP pipeline, first, for the semantic and syntactic approach, the earlier mentioned CWN project will offer corresponding tools for sense tagging and construction extraction, respectively. Secondly, for aligning sound and text, tools providing semi-manual forced alignment may be suitable to be deployed, we are now seeking an opportunity to collaborate with members from the phonetics labs in our institute. Lastly, for establishing multimodal corpus, ELAN is a great solution for annotating our audiovisual recordings. Currently, we are working on organizing the criteria of annotating the information emerging from the kinetic tier, which is considered to be the soul of multimodality. By collaborating as the members of Red Hen, our goal is to provide a multilingual multimodal corpus with a sophisticated query system.
Goals
The expected goals under this research proposal would be two-fold—for the theoretical studies on multimodal communication, lexical semantics and construction grammar may shed unique insights in multimodal linguistic research. At the same time, we would be excited to join Red Hen as a collection site and devote ourselves to the four categories of Taiwanese languages data—Taiwan Mandarin, Taiwanese Hokkien, Taiwanese Hakka, and Formosan languages. As the study progresses, we would also be glad to contribute our works on Chinese NLP, multimodal annotations, and code tools to help make the overall process pipeline better.